


(图片来源:摄图网)
8月27日,华为董事、质量流程IT总裁陶景文在第四届828 B2B企业节上表示,“以华为为龙头的硬件公司,在算力上应该已经能够基本解决美国对中国的卡脖子问题。中国还有一批像DeepSeek这样的优秀大模型公司,我们在大模型竞争力上已经不输于美国公司。”他在发言时强调,中国企业不仅要关注算力,还要实现业务场景、算力、模型和数据的有效结合,这才是真正的人工智能。
中国在人工智能领域的快速发展,尤其是大模型的崛起,已经成为全球关注的焦点。数据显示,截至2024年第一季度,中国人工智能大模型累计发布数量已达478个,仅次于美国。
中国大模型产业的崛起,不仅体现在数量规模上,更在于技术体系的成熟。通过前期在人工智能领域的系统性部署,中国已建立起涵盖理论方法、算法框架、软硬件协同的完整研发体系。在自然语言处理、计算机视觉等关键领域,涌现出如DeepSeek等具备国际竞争力的大模型企业,其模型性能在多项基准测试中达到或超越国际领先水平。
自建算力是构筑大语言模型核心竞争力的关键因素。在人工智能领域,尤其是大语言模型的开发和应用中,算力不仅是推动模型训练和优化的基础,更是提升模型性能、实现快速响应和精准输出的保障。
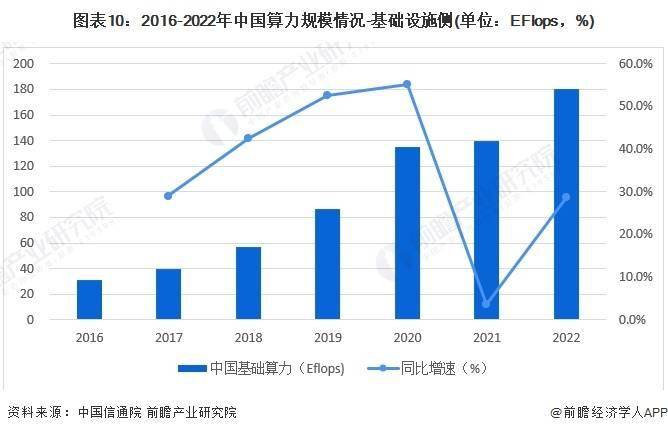
随着全国一体化算力网络国家枢纽节点的部署和“东数西算”工程的推进,我国算力基础设施建设和应用保持快速发展。。2017-2022年,中国算力规模呈现逐年上升的状态。根据中国通信院披露的信息,2022年,我国算力规模为180 EFlops,同比增长28.6%,位居全球第二,算力总规模近五年年均增速超过了25%。
中国科学院计算机网络信息中心研究员陆忠华认为,随着AI的发展,AI服务的算力需求越来越多了,而且趋势是不可阻挡的,我们应该去迎接这个趋势。如何满足大家日益增长的算力需求,在5—8年的时间里,应该努力用好已经建设的超算中心、智算中心,使得已经投入建好的中心资源不要浪费。可以率先尝试在某些领域开展大模型应用,鼓励生态建设。另外,构建人工智能基础设施体系,不应过分强调一体化布局,还是应该在国家政策指导下支持百花齐放,把剩下的交给市场。
中国科学院院士陈润生表示,用大模型学术基础构架专业模型,既能达到高精度又能实现小能耗。他认为,人工智能算力服务要有布局也要有分工,不要一拥而上,也不要半途而废,要避免资源浪费。
前瞻经济学人APP资讯组
更多本行业研究分析详见前瞻产业研究院《》
同时前瞻产业研究院还提供、、、、、、、、、、、等解决方案。如需转载引用本篇文章内容,请注明资料来源(前瞻产业研究院)。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






